Spoken corpus of Meadow Mari
(as spoken
in the village of Staryj Toryal, Novyj Torjal district, Mari El Republic, Russia)
The corpus contains spoken texts in Meadow Mari (also known as Eastern Mari or formerly Cheremis, M.Mari: Олык марий, Russian: луговой марийский язык; glottocode [mhr]).
The texts for the corpus were recorded in 2000–2004 and in 2018 in the village of Staryj Torjal (Novyj Torjal district, Mari El Republic) and belong to the Sernur-Morkin dialect. This dialect forms the basis of the literary Meadow Mari (Bartseva et al., 2012), thus the corpus texts are close to literary Meadow Mari, but display some non-standard lexical and morphological properties.
Search
Transliteration
The corpus texts are written in the Meadow Mari alphabet which is based on the Cyrillic alphabet plus a few additional letters (see table 1). In order to facilitate searching through the corpus the orthography of the texts was normalized as much as possible meaning it does not reflect the phonetic dialectal variation. For instance, the dialect form kəlm-en-ut /freeze-pst2-3pl/ with a dialectal marker -ut instead of -ət used in literary Meadow Mari is spelled as кылменыт.
The mapping between the Meadow Mari alphabet, the IPA transcription and the transcription adopted in Kuznetsova et. al (2012) is shown in Table 1.
For narrow phonetic transcription we recommend consulting the audiofile of the corpus.
| letter | sound (phone): IPA, [Kuznetsova et al., 2012] | letter | sound (phone): IPA, [Kuznetsova et al., 2012] | letter | sound (phone): IPA, [Kuznetsova et al., 2012] |
| А а | a | Л л | l | Ф ф* | f |
| Б б | b | М м | m | Х х | x |
| В в | v | Н н | n | Ц ц | ts, c |
| Г г | g | Ҥ ҥ | ŋ | Ч ч | t̠ʃ, č |
| Д д | d | О о | o | Ш ш | ʃ, š |
| Е е | e (after a consonant), je (in the beginning of a word, after a vowel, after ъ and ь) | Ӧ ӧ | ɵ, ö | Щ щ* | t͡ɕ |
| Ё ё* | o (after palatalized consonants), jo (in the beginning of a word, after a vowel, after ъ and ь) | П п | p | Ъ ъ | - |
| Ж ж | ʒ, ž | Р р | r | Ы ы | ə |
| З з | z | С с | s | Ь ь | - as part of digraphs ль and нь marks palatalization /l’/ and /n’/ |
| И и | i | Т т | t | Э э | e |
| Й й | j | У у | u | Ю ю | u (after palatalized consonants), ju (in the beginning of a word, after a vowel, after ъ and ь) |
| К к | k | Ӱ ӱ | y, ü | Я я | a (after palatalized consonants), ja (in the beginning of a word, after a vowel, after ъ and ь) |
Asterisk (*) indicates letters that are used only in Russian loanwords
As becomes evident from Table 1, the letters е, ю, я, ё are used for iotized vowels. However, ё is only used in Russian loanwords.
In words which are not recent Russian loanwords iotized vowels would be spelled using only е, ю, я (еҥ ‘man’, юлгыжаш ‘twinkle’, янлык ‘beast’) or a combination of й and a vowel (йылме ‘language’, йӧраташ ‘love’, йӱлаташ ‘burn’).
Cf. ёлка ‘fir-tree’ which contrasts with йолташ ‘friend’
Creators
The texts were prepared for publication as a corpus in 2018–2021. This process included:
Project participants:
Some of the corpus texts were recorded and transcribed in 2000-2004 by the participants of the fieldwork trips to Staryj Torjal. These field trips were organized by the Department of Linguistics (OTiPL) of the Lomonosov Moscow State University and were headed by Ariadna I. Kuznetsova, Elena Kalinina and Svetlana Toldova. The members of the field trips thus contributed to the expansion and preparation of the corpus, we list them below:
Ariadna I. Kuznetsova, Svetlana Toldova, Maria Brykina, Anna Volkova, Dmitry Kolomatsky, Natalia Latysheva, Alexandra Sudobina, Olga Tretiakova, Evgenia Chernigovskaya, Alexander Arkhipov, Fedor Rozhankiy, Natalia Serdobolskaya, Andrey Khitrov, Nina Sumbatova, Alexandra Simonenko, Natalia Shibasova, Anna Shikhova, Elena Kalinina, Marina Chumakina, Anfisa Ilyevskaya, Alexander Egorushkin, Valentin Gusev, Alexander Kibrik, Sandro Kodzasov.
The corpus texts are published for the first time with two exceptions – the texts “Scrap metal” (Металлолом) and “Cucumbers” (Огурцы) recorded by Elena Kalinina, glossed by Maria Brykina and prepared for publication by Svetlana Toldova were previously published in the collection of papers Finno-Ugric Languages: Fragments of grammatical description.
Acknowledgements
The authors wish to express their deepest gratitude towards the people of Staryj Torjal for the warm welcome and inexhaustible hospitality, for their contribution to the field study of the Meadow Mari language over the last twenty years, for their incredible patience and good humor when discussing questions of Mari grammar.
The Spoken Corpus of Meadow Mari (as spoken in the village of Staryj Toryal, Novyj Torjal district, Mari El Republic, Russia) is a result of work conducted within the framework of the HSE University Basic Research Program.
How to use the corpus
This section outlines the capabilities of the tsakorpussearch engine that is attached to the Corpus. The general instructions on the technical possibilities of the tsakorpus search engine can be found in the section “Help” (the button with a question mark in the top right corner of the search engine page). Here we limit ourselves to the rules which are specific to this Corpus.
The main page contains the form with the fields “Word”, “Lemma”, “Grammar”, and “Glosses”.
How to search for the exact word form (“Word”)
If you want to find all the uses of a certain word form, you can enter in the field “Word”. For example, to find all the entries of the locative case form школышто ‘at school’ of the noun школ ‘school’, the form школышто should be entered in the field “Word”.
To use regular expressions and to learn about other options of using the field “Word”, please, consult “Help”.
How to search for lexemes (“Lemma”)
This field should be used to find all forms of a certain word (lexeme). For example, if you enter the word школ ‘school’ into the “Lemma” field, the search results will list all the entries containing this noun in all the attested forms, e.g. школ ‘school’, школ-ышто [school-LOC] ‘at school’, школ-ышты-жо [school-LOC-3SG] ‘at his school’ etc.
To search with this field one should use the base form, namely the form that is usually used as a head word in the Mari dictionary. For nouns and pronouns the base form is the Nominative singular form (e.g. пӧрт ‘house’, тый ‘you’); for adjectives, adverbs, and numerals the base form is self-explanatory (e.g. изи ‘small’, кызыт ‘now’); for verbs the form ending in -аш is used (e.g. ышташ ‘do’, налаш ‘take’). For numerals the short and the long forms constitute different lemmas (e.g. кум ‘three (short)’ and кумыт ‘three (long)’).
The Corpus search engine does not draw a distinction between inflection and derivation. This means that the forms derived in a regular way are considered to be forms of a lemma. For example. the verb лӱдыкташ ‘scare’ which in Mari dictionaries is treated as a lexeme, in the Corpus is considered a causative form of the verb лӱдаш ‘be afraid, scared’. Consequently, if “лӱдыкташ” is entered in the field “Lemma”, the search engine will not return any results, while for “лӱдаш” it will show both the forms without a causative marker (e.g. лӱдынам ‘(she/he) got scared’) and the forms with it (e.g., лӱдыктена ‘we will scare’ ). To search solely for causative forms, one can narrow down the search results by using the fields “Grammar” and “Glosses”. Similar decisions have been made for several other derivational processes (see “Grammar”).
Non-regular verbal forms улмаш and улмашын are considered the forms of the verb улаш ‘be’.
Grammar
The field “Grammar” allows searching for specific parts of speech and grammar categories. To use these options, one needs to push the button in the right part of the field “Grammar”, a help window will appear where one can choose the relevant grammatical properties.
The tags used in the “Grammar” field are listed below.
Parts of speech
Parts of speech (POS) tags in the Corpus are associated with the first morpheme in any given word form, which is normally the root. As a consequence, every word form is treated by the Corpus as if it represents the part of speech associated with the root. Derivational affixes that change part-of-speech membership are disregarded. For example, the word form вашлиймаш [meet-NMLZ] ‘meeting’ can appear among search results if one uses “verb” (v) rather than noun (n) as the relevant part of speech tag, even though this word form has syntactic properties of a noun.
v – verb;
n – noun;
adj – adjective;
adv – adverb;
num – numeral;
pro – pronoun;
post – postposition;
conj – conjunction;
part – particle;
intrj – interjection;
imit – onomatopoeic word.
Lexical noun classes; derivations
PN – personal noun (subtype of nouns);
topn – toponym;
persn – personal name;
famn – family name;
patrn – patronymic;
anim – animate noun;
hum – noun denoting a human;
supernat – noun denoting a supernatural being;
transport – transport;
body – body part;
Nominal derivations
attr — any attributive;
attr_an — general attributive in -ан;
attr_le — attributive in -ле;
attr_loc — locative attributive in -се;
attr_neg — negative attributive in -дыме;
abbr – abbreviation;
rus – loanword from or through Russian.
Pronominal classes
pers — personal pronoun;
dem — demonstrative pronoun;
refl — reflexive pronoun;
indef — indefinite pronoun.
Agreement
The agreement features of person and number are listed in the subsections tooltip_Person and tooltip_Number respectively.
At the moment the person feature is defined only for pronouns (not for all noun phrases). The next planned step will be to define the person and number features for all noun phrases and verbal forms.
Glosses
The field “Gloss” allows users to submit search queries that concern the morphemic structure of the word forms. In general, this type of search is functionally similar to the search in the field “Grammar”. In particular, the list of markers that can be viewed by clicking the button next to the field “Gloss” largely overlaps with those given in the field “Grammar”.
The general principle of search by a gloss and the major differences of this type of search from the grammatical search are described in the “Help” section (the button with a question mark in the top right corner of the search window). Below we list glosses used in the Corpus with some explanations.
Nominal categories
| ∅ | SG | singular |
| -влак, -шамыч | PL | plural |
Case
| ∅ | NOM | Nominative |
| -(ы)м | ACC | Accusative |
| -(ы)н | GEN | Genitive |
| -(ы)лан | DAT | Dative |
| -еш / -эш | LAT | Lative |
| -(ы)ште, -(ы)што, -(ы)штӧ | LOC | Locative |
| -(ы)шке, -(ы)шко, -(ы)шкӧ | ILL | Illative |
| -ге | COM | Comitative |
Possessive markers
| ∅ | NONPOSS | without a possessive marker |
| -ем/ -эм, -м | 1SG | 1st person singular (my) |
| -на | 1PL | 1st person plural (our) |
| -ет/ -эт, -т | 2SG | 2nd person singular (your) |
| -да | 2PL | 2nd person plural (your) |
| -(ы)же, -(ы)жо, -(ы)жӧ; -ше, -шо, -шӧ. | 3SG | 3rd person singular (her/his) |
| -ышт | 3PL | 3rd person plural (their) |
Verbal categories
Verb conjugation in the Staryj Torjal dialect is identical to the one in literary Meadow Mari. Paradigms can be found here:
http://grammar.marlamuter.com/morf_verb.php
Main verb forms
| cumulative person-number markers in the non-past tense | NPST | non-past |
| cumulative person-number markers in past I | PST | past I |
| -ын / -ен + cumulative person-number markers of past II | PST2 | past II |
| -аш | INF | infinitive |
| -∅ | IMP.2SG | imperative 2nd person singular |
| -за/ -са/ -да | IMP.2PL | imperative 2nd person plural |
| -же/ -жо/ -жӧ -ше/ -шо/ -шӧ | IMP.3SG | imperative 3rd person singular |
| -ышт | IMP.3PL | imperative 3rd person plural |
| NEG | negative verb |
Regular verbal derivations
| -тар, -дар, -(ы)кт, -т, -д | CAUS | causative (‘make someone do something’) |
| -алт, -ылт, -ялт | PASS | passive voice |
| -ылдал, -алал, -ал, -ялал, -ял | ATT | attenuative (verbal form indicating attenuation, reduction of the intensity of action) |
| -алт, -ялт | PNCT | punctive (aspectual meaning of a ‘singular event’) |
Non-finite markers
| -(ы)маш | NMLZ | nominalization |
| -(ы)шаш, -(ы)шашлык | PTCP.PROSP | prospective (debitive) participle |
| -(ы)ше/ -(ы)шо/ -(ы)шӧ | PTCP.ACT | active participle |
| -(ы)ме/ -(ы)мо/ -(ы)мӧ | PTCP.PASS | passive participle |
| -(ы)дыме/ -(ы)дымо/ -(ы)дымӧ | PTCP.NEG | negative participle |
| -ен/ -эн/ -ын / -∅ | CVB.GEN | simple converb |
| -(ы)шыла, -(ы)мыла | CVB.SIM | simultaneity converb |
| -(ы)де/ -(ы)дегече/ -(ы)дегызе | CVB.NEG | negative converb |
| -(ы)меке, -(ы)мӧҥгӧ/ -(ы)меҥге | CVB.CONSEC | posteriority converb |
| -(ы)мешке | CVB.PREC | precedence (anteriority) converb |
Clitics
| -рак | COMP | comparative suffix (degree of comparison) |
| -ат, -т | ADD | additive particle (‘too’) |
| -ак, -к | EMPH | emphatic identity particle |
| -я | HORT | hortative particle |
Translation
Using these fields allows users to search for word forms based on the Russian/English translation of respective lemmas. For example, inserting “do” in the field “Translation (eng)” will render all the entries of the verb ышташ, as its root is translated as ‘do’. These fields do not allow searching for Russian or English word forms used in the translations of Mari sentences. For example, one would not be able to find all the sentences that contain “have done” in their translations using “Translation” fields, instead to achieve this result, one should use full-text search.
Additional search possibilities
Our Corpus further allows configuring search based on the parameters “Speaker” and “Gender”. Certain speakers can be excluded from search results by using the ~ symbol. By default, the search results do not include the phrases of one of the interviewers who didn’t speak Mari.
All other search parameters (full-text search, sentence/ word/ lexeme search, selecting a subcorpus, simultaneous use of several fields, several word forms search etc.) are not specific for the Spoken Meadow Mari Corpus.
Code-switching
The Corpus texts contain fragments that were uttered in Russian.
Some of them were uttered by the interviewers who didn’t speak Meadow Mari. Others were uttered by the Mari native speakers as answers to the interviewers’ phrases in Russian. Finally, in certain cases Mari native speakers switched to Russian for other reasons. These latter situations represent inter-sentential code switching (Poplack 1980).
If a certain fragment was uttered solely in Russian, its code switching status was marked with ru.
On the search page (more fields > Metafield_cs) one can constrain the search limiting it to fragments uttered in Russian (select metavalue_ru) or to fragments in Meadow Mari (metavalue_~ru). If the field is left empty, the search will run through the entire corpus regardless of the language. By default, metavalue_~ru is preselected.
Corpus composition
The corpus contains 23 texts with the total duration of just over three hours, its volume totals 11647 tokens (of which 9088 are in Meadow Mari).
Figure 1 shows how many tokens in the Mari part of the Corpus belong to each of the speakers (aav is the interviewer who doesn’t speak Meadow Mari):
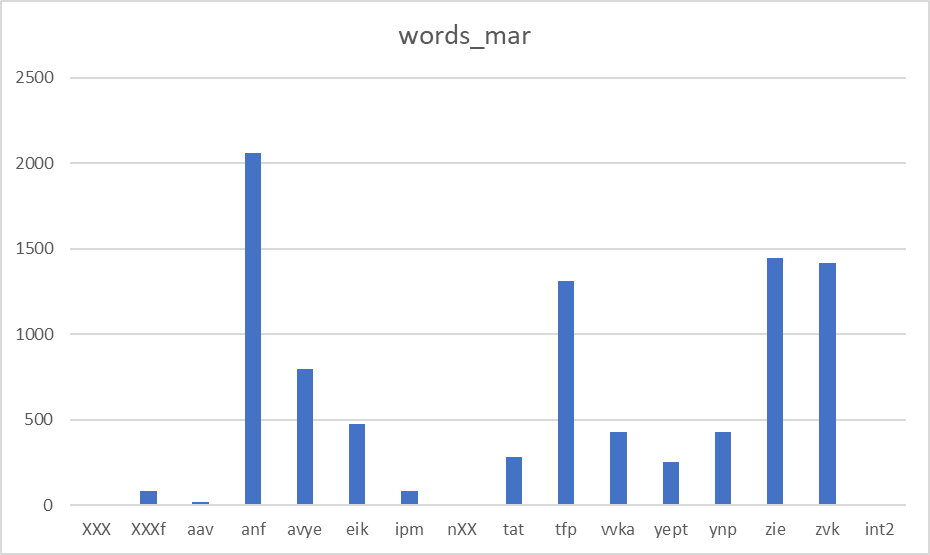
Figure 2 demonstrates the distribution of tokens in both Meadow Mari and Russian across the speakers.
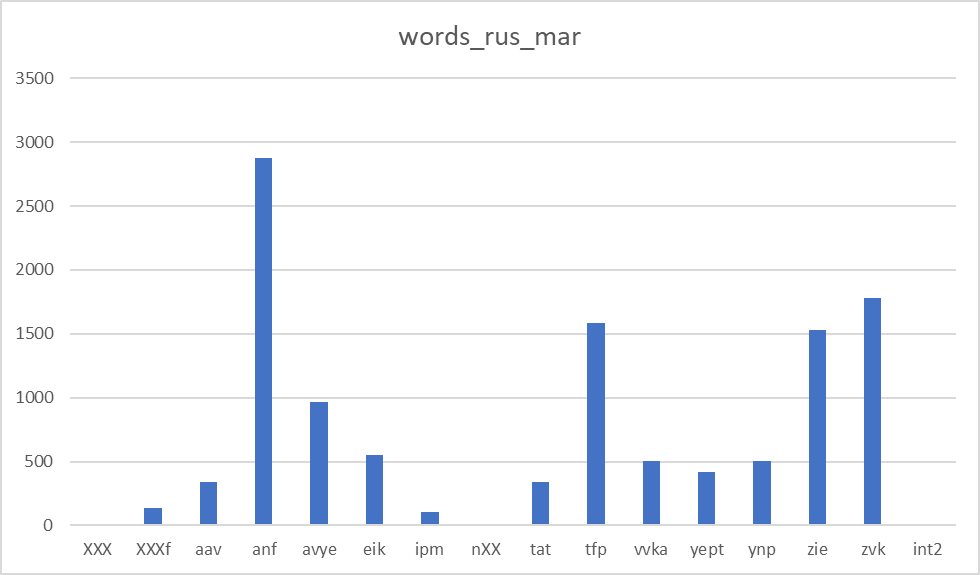
Figure 3 illustrates the distribution of phrase length across different speakers (for both Meadow Mari and Russian phrases):
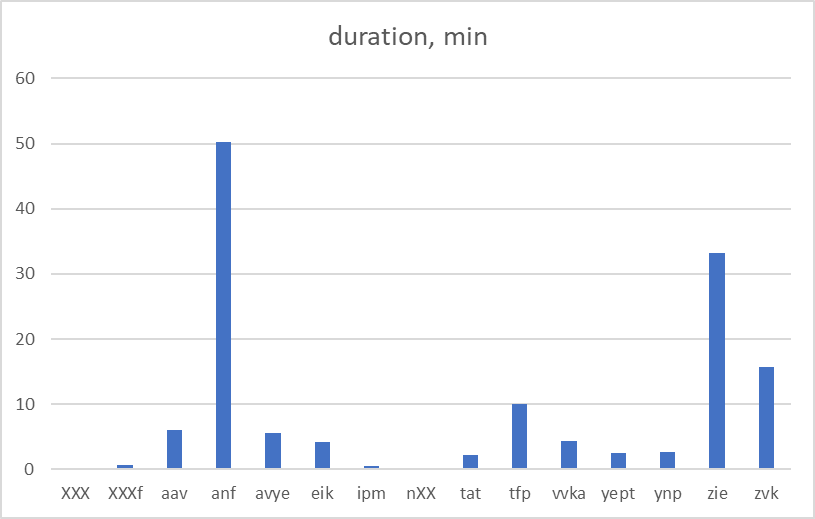
The Corpus texts were recorded from 11 native speakers of different age groups who were born between 1930 and 1990. The speakers’ age distribution is shown in the table below.
| Birth year | Number of speakers |
| 1930–1940 | 2 |
| 1941–1950 | 1 |
| 1951–1960 | 4 |
| 1961–1970 | 1 |
| 1971–1980 | 1 |
| 1981–1990 | 2 |
Most of the texts are dialogues, interviews conducted by Anna Volkova, Zinaida Klyucheva who also lives in Staryj Torjal and one anonymous Russian speaker. Apart from that there are also a number of semi-spontaneous monologues and several dialogues. Figure 4 shows the genre-thematic compositions of the Corpus in recording minutes.
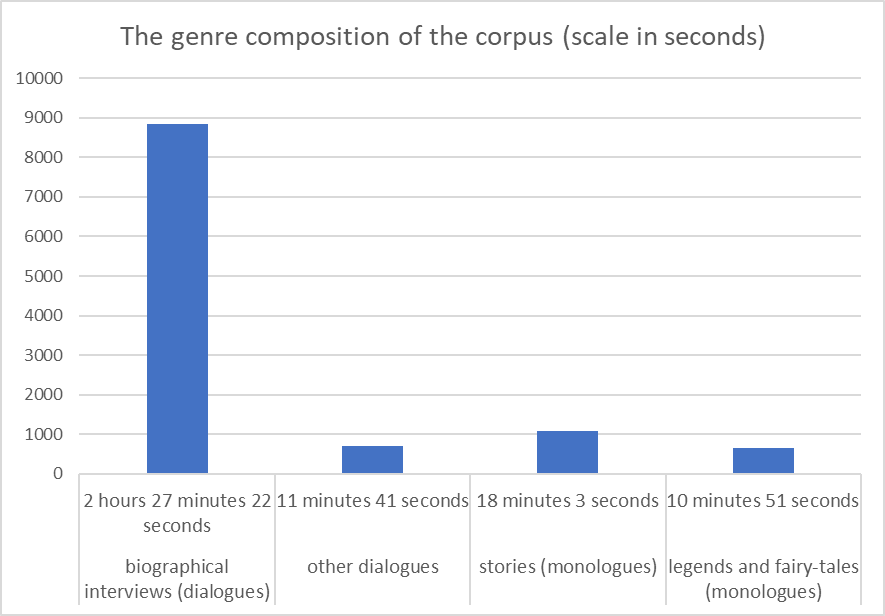
Other Meadow Mari resources
Corpora:
| http://meadow-mari.web-corpora.net/index_en.html | Meadow Mari corpora created by Timofey Arkhangelsky: 1) Main corpus of literary Meadow Mari (at the moment primarily consists of newspaper texts); 2) Mari social networks corpus. |
| http://gtweb.uit.no/u_korp/?mode=mhr#?lang=en&stats_reduce=word&cqp=%5B%5D | Corpus of Literary Mari Korp created by a group of authors (Trond Trosterud, Jeremy Bradley, Jack Rueter, Alexandra Simonenko, Anna Volkova, Niko Partanen, Jorma Luutonen, Andrey Chemyshev, Gennadiy Sabantsev, Nadezhda Timofeeva): about 57,38 mln tokens in Meadow Mari |
| http://corp.marnii.ru/# | Literary Meadow Mari Corpus created by MarNIIJALI (Mari Scientific Research Institute of Language, Literature and History), about 20,67 mln tokens |
Mari electronic library:
Page summarizing various resources in Mari languages.
Contacts
Content questions:
Aigul Zakirova: aigul.n.zakirova@gmail.com
Technical questions:
Elena Sokur: elena.o.sokur@gmail.com
How to cite the Corpus
If you are using the Corpus data in your research, please, cite it as follows:
References
Bartseva, L. I. et al. (2012). Morkinsko-sernurskij govor marijskogo jazyka [Sernur-Morkin dialect of Mari].
Kuznetsova, A. I. (Ed.) (2012). Finno-ugorskie jazyki. Fragmenty grammaticheskogo opisanija [Essays on the grammar of Finno-Ugric languages]. Moscow: Rukopisnye pamyatniki Drevnej Rusi.
Poplack S. Sometimes I’ll start a sentence in Spanish Y TERMINO EN ESPAÑOL: Toward a typology of code-switching // Linguistics. 1980. № 18(7–8). С. 581–618.